Motivation & Overview
Predicting crystal structures from chemical compositions is a fundamental challenge in materials discovery — analogous to protein folding but with far more complex 3D geometries.
High Computational Cost
Traditional CSP methods — first-principles calculations, stochastic sampling, and evolutionary optimization — are inherently limited by high computational costs and poor scalability with system complexity.
Limited Generalizability
Existing deep generative models rely on domain-specific small datasets for training, leading to limited generalizability to unseen structures and unsatisfactory performance on widely recognized CSP benchmarks like MPTS-52.
Missing CSP-Specific Foundation Models
Prior crystal foundation models either target force-field prediction (GNoME, MACE-MP-0) or general-purpose generation (MatterGen) — none specifically targets CSP with thorough investigation.
Our Solution: Siamese Foundation Models
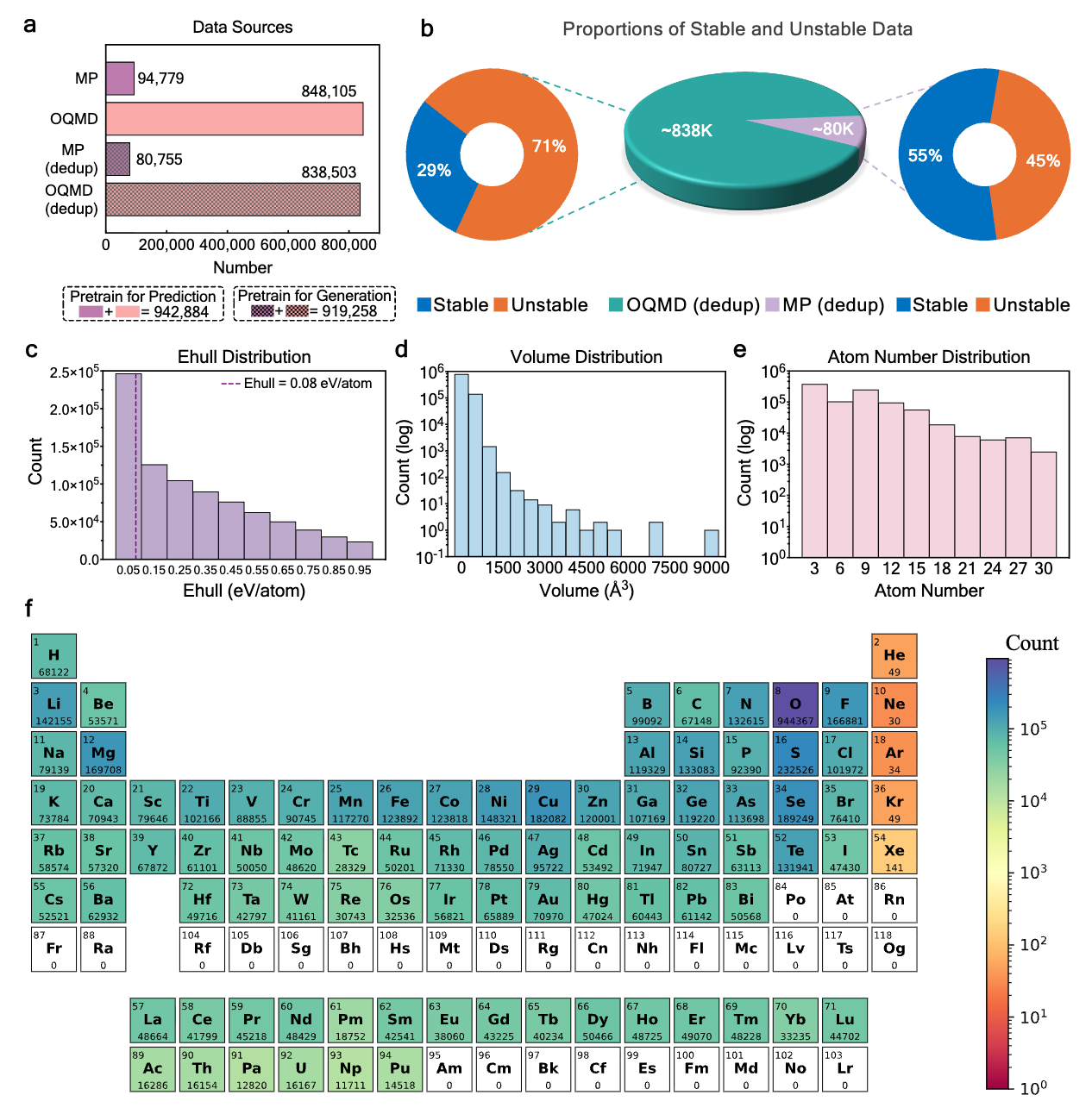
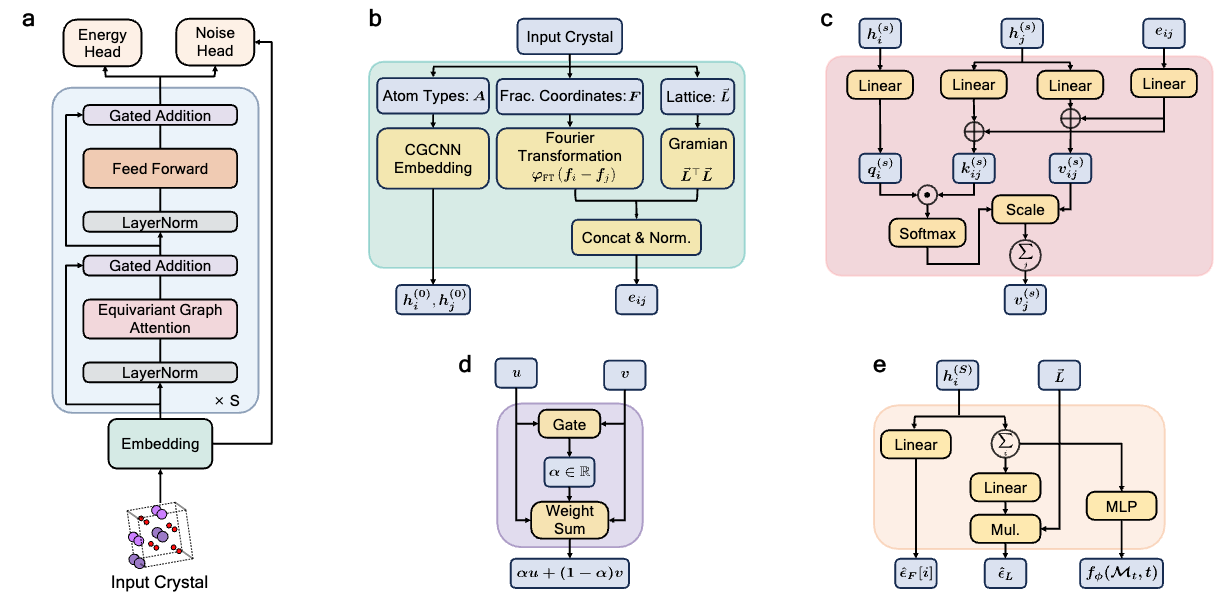
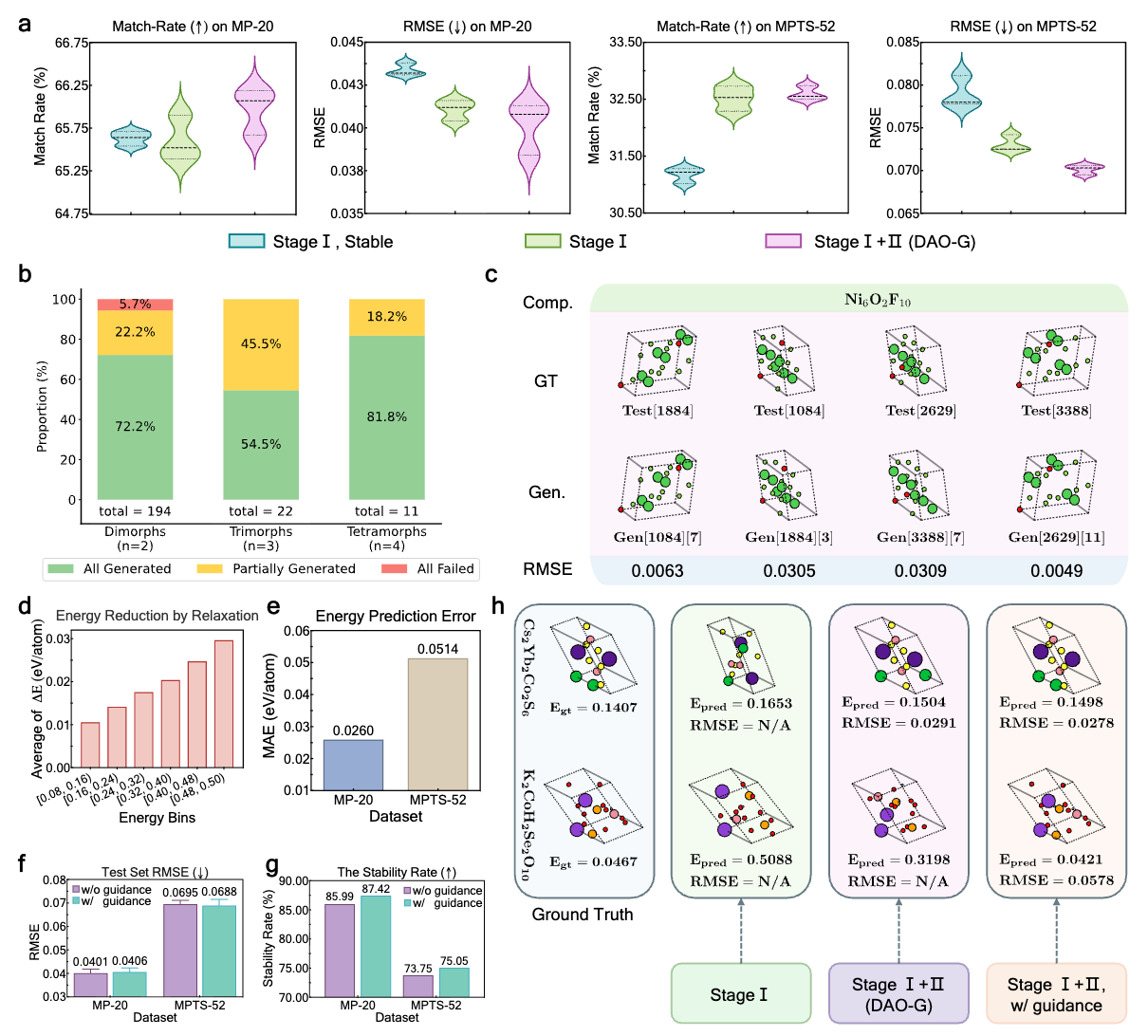
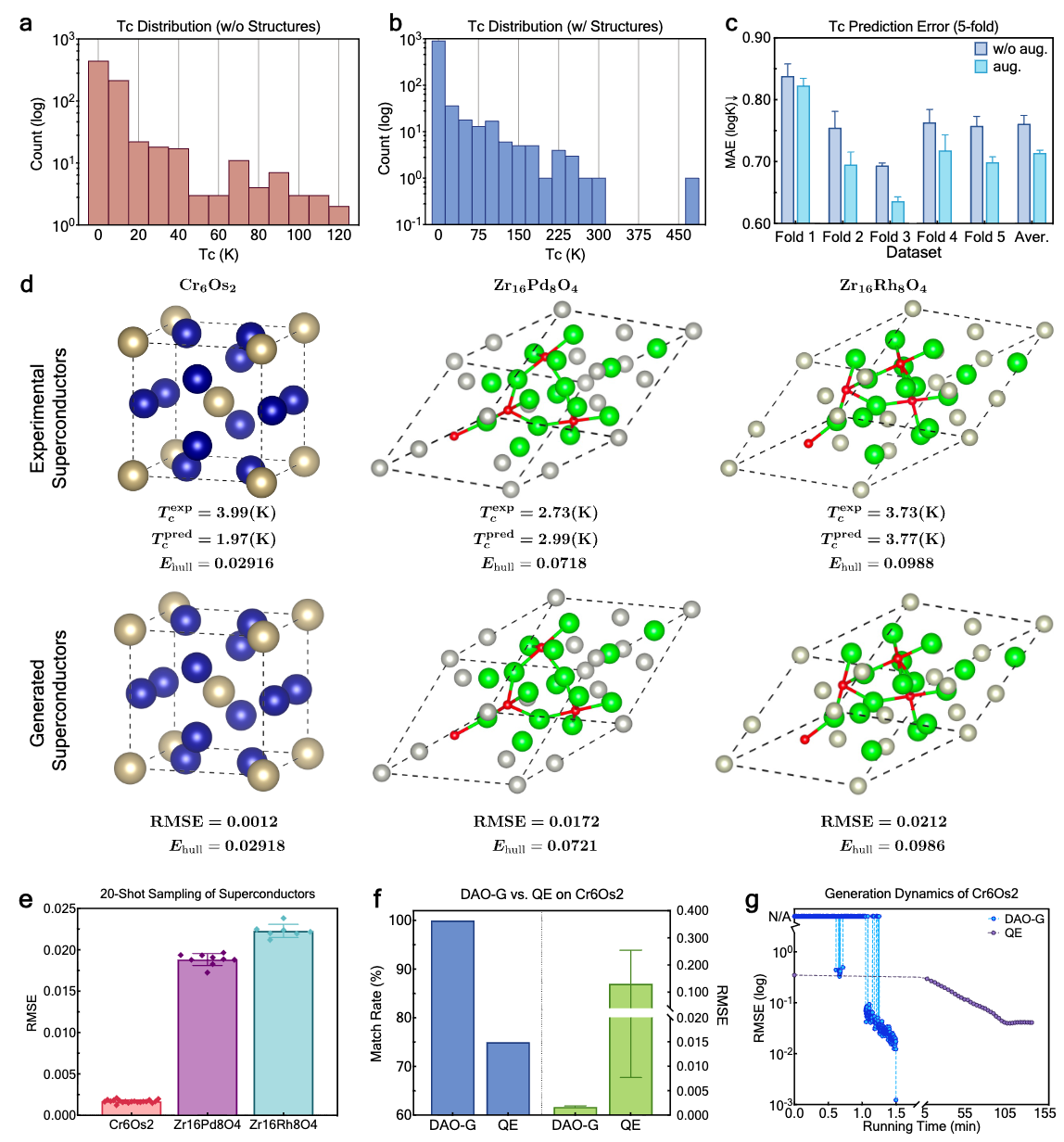
We propose Diffusion-based Crystal Omni (DAO), a pretrain–finetune framework comprising two complementary foundation models: DAO-G for generating stable crystal structures and DAO-P for predicting energy and assisting DAO-G. Both are built upon Crysformer, a geometric graph Transformer ensuring O(3) and periodic invariance for crystal structures.
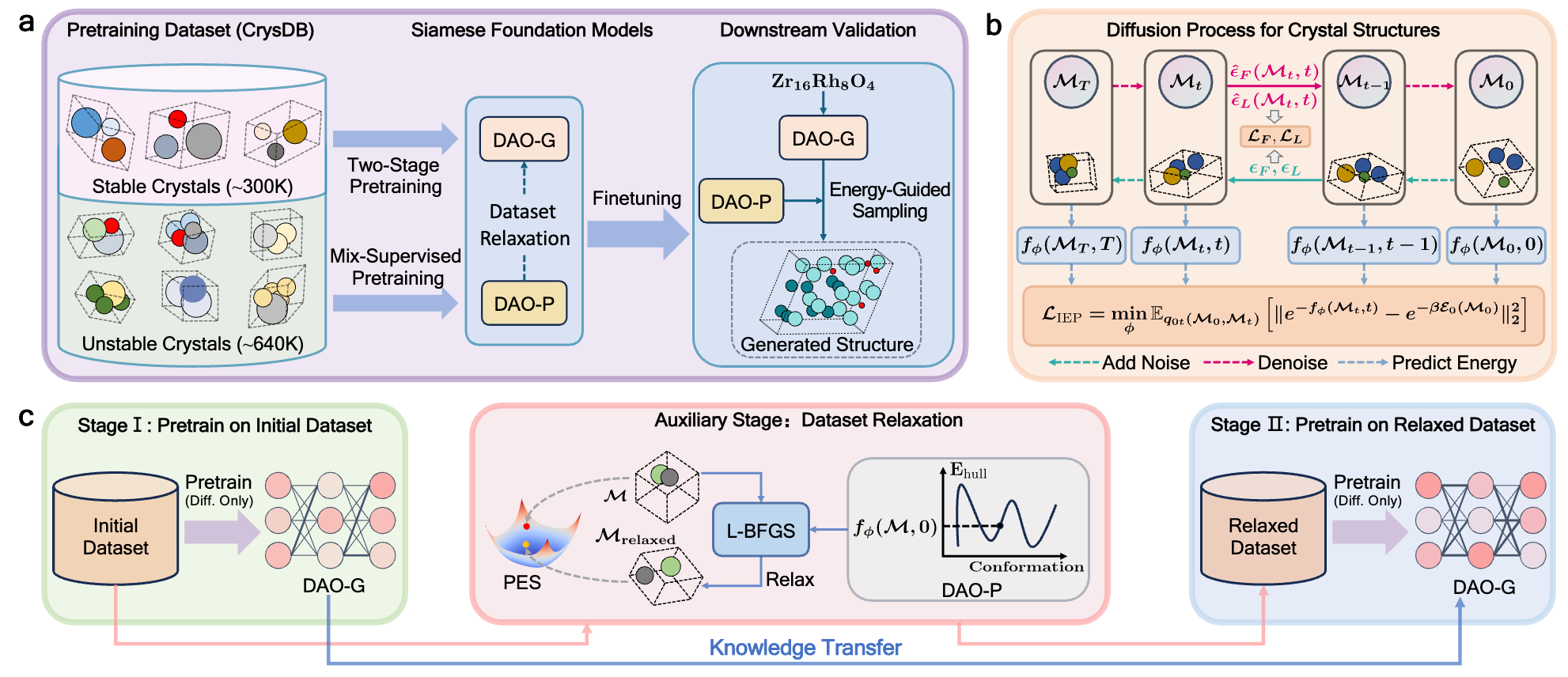
The DAO framework: pretraining pipeline and downstream validation of DAO-G and DAO-P.